|
詞彙
1. 基礎部件 (Basic Component)
最小的不再拆分的部件稱為“基礎部件”。基礎部件是漢字結構的最低層部件,又稱末級部件。例如:“男”中的“田”、“力”。(參見
- 漢字部件)
2. 大五碼 (Big5)
一套在台灣及香港普遍採用的中文編碼工業標準,收納了約13,000個繁體中文字符。(參見
- 國家標準碼、統一碼)
3. Big-endian
是一種電腦存儲結構,將多字節的數值按高位到低位存放。(參見 -UTF-16)
4. 塊 (Block)
一組連續的編碼區域,其中的整套字符具有共同的屬性特徵,如某一文字的字母集。兩塊區域之間不交疊。區域中的部分編碼位可能沒有定義字符。
5. BMP
是《基本多文種平面》的英文字母縮寫,即是UCS-4的第一個平面,即00組中的00平面。亦是2
字???(UCS-2)的主平面。(參見 - UCS-2, UCS-4)
6. 正則形式 (Canonical form)
ISO/IEC 10646字符集中的正則編碼,以四個八位字節表示一個字符。UCS-4是ISO/IEC
10646的正則形式。(參見 - UCS-4)
7. 編碼字符數據元素 (Coded-Character-Data-Element)
是一個可交換信息用的元素。用於組成一些字符的編碼序列,協調存在于一或多個特定的編碼字符集標準中。例如:某些文本,如拉丁文中,需要用到讀音符號,比如:
" "加到字母" "加到字母"
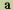 "上,變成" "上,變成" 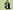 "。""本身不是一個字符,但是一個字符集標準中的數據元素。當然,字母本身根據定義也是編碼字符數據元素。(參見
- 編碼字符集) "。""本身不是一個字符,但是一個字符集標準中的數據元素。當然,字母本身根據定義也是編碼字符數據元素。(參見
- 編碼字符集)
8. 單元 (Cell)
一般指一個編碼位。在雙字節編碼中,用第一字節表示行,第二字節表示列來定位一個碼位。在二維數組中,單元表示橫向軸上的值。(參見
- 行)
9. 字符 (Character)
用於表達、組織或控制抽象概念元素中的一個元素。它通常是表示一種語言或符號的獨立元素,亦可作電腦字符集,字母集或漢字集的一個元素。(參見
- 字形、漢字)
10. 字符分界線 (Character Boundary)
在八位字節數據流中的分界線,用來界定一個字節一個編碼字符的末字節和下一個編碼字符的首字節。
11. 字符拆分 (Character Decomposition)
分柝及拆解文字元素為多個部件單位。這些部件單位不一定具有實用功能,但可以是外形單元或抽象形狀。中文字符可以按部件或筆畫拆分。
12. 字符編碼方案 (Character Encoding Scheme)
字符集元素到編碼字節元素的映射。(參見 - 字符集、編碼字符集)
13. 字符集 (Character Set)
電腦上用於表達、組織或控制信息的一個字符集合。(參見 - 編碼字符集)
14. 字符認同 (Character Unification)
將多個字符統一認同為一個字符的處理過程。認同標準可以根據字符的抽象形式或抽象功能界定。字符統一認同可以避免將本質上相同的字符分別賦予多個不同的碼位。
15. 漢字部件 (Chinese Character Component)
由筆畫組成的具有組配漢字功能的構字單位。簡稱“部件”。例如:“木、心、口、也”。漢字的偏旁部首均是部件。
16. 中日韓統一漢字集 (CJK Ideographs)
ISO/IEC 10646 標準中的簡繁體中文,日文、韓文和越南文中的漢字集。(參見
- 漢字)
17. 中日韓統一漢字認同規則 (CJK Ideographs Unification)
ISO/IEC 10646中收集的漢字是通過一套認同規則和程序,從漢字字源中挑選出來的。目的是避免將本質上相同而形狀上稍有差異的字符分別賦予多個不同的碼位。沒有字源關係的形似字符不會被認同,如“士”和“土”會分別編碼。而其他外形相似的所謂“異體字”則依照兩層分類原則來區分,(a)抽象字形間差異;(b)具體字樣字形間差異,
用以界定是否分別編碼。
18. 編碼字符 (Coded Character)
字符及其編碼表示。
19. 編碼字符集 (Coded Character Set)
編碼字符的集合。集合中的每一個字符都賦予一個數值碼。在上下文清晰的情況下,通常簡稱為字符集。(參見
- 字符集)
20. 組合用字符 (Combining Character)
ISO/IEC 10646編碼字符集中一種結構要素,用於與其前導的非組合用圖形字符相組合,或者與一個以非組合用字符為前導的組合用字符序列相組合。比如組合用字符""加到非組合用圖形字符字母""上,形成字母""。
21. 兼容字符 (Compatibility Character)
ISO/IEC 10646 中為達到與原編碼字符集兼容而未被統一認同的字符,用作保証雙向轉碼的正確性
。 (參見 - 轉碼)
22. 復合序列 (Composite Sequence)
有一個非組合用字符後面跟著一或多個組合用字符而組成的圖形字符序列。(參見
- 組合用字符)
23. 字形 (Glyph)
將抽象觀念的字符,以一個有形的圖形表示出來。一個中文字形給出字符的基本幾何結構,包括筆畫的組合方式,筆畫的相對位置與大小。(參見
- 字符)
24. 圖形字符 (Graphic Character)
除控制功能符之外的具有可視化的字符。可手寫、打印和顯示。
25. 圖形符號 (Graphic Symbol)
圖形字符或由復合序列來描述的可視化字符。(參見 - 復合序列、圖形字符)
26. 組 (Group)
ISO 10646定義了128組,每組有256個平面,而每個平面有256行和256列,每組共256
x 256 x 256個編碼位。
27. 國家標準碼 (GB)
是按中國政府的國家編碼標準製定的字符集。此字符集應用於中國內地、新加坡及其他採用簡體漢字的地方。
(參見 -大五碼、統一碼)
28. 漢字字符 (Han Characters)
以中文為主的表意字符。
29. 漢字 (Hanzi)
記錄漢語的書寫符號系統,漢字也被其他一些國家或民族用作為書寫符號。
30. 高半代理區 (High-half Zone,Range U+D800-DBFF)
一組預留的編碼集合,用于在UTF-16代理區編碼中表示高位字節,來映射在BMP以外平面上的編碼字符位。
(參見 - 低半代理區,UTF-16)
31. 表意文字 (Ideograph)
表意文字指書寫系統主要是表其『意』而不表其『聲』,漢字屬于表意文字。(參見
- 漢字字符)
32. 交換 (Interchange)
利用電信或其他交換媒介,由一個用戶向另一個用戶傳送字符編碼數據,而不丟失數據的過程。(參見
-編碼字符)
33. 交互運作 (Internetworking)
在兩個或多個使用不同編碼字符集的系統之間,做含義確切的字符編碼數據交換過程。其中可能涉及兩種代碼之間的轉換。(參見
- 編碼字符集)
34. Little-endian
是一種電腦存儲結構,將多字節的數值按低位到高位存放。(參見 -UTF-16)
35. 低半代理區 (Low-half Zone, Range:U+DC00-DFFF)
一組預留的編碼集合,用于在UTF-16代理區編碼中表示低位字節,來映射在BMP以外平面上的編碼字符位。
(參見 - 高半代理區, UTF-16)
36. 八位字節 (Octet)
作為一個整體單元來處理的一組八個二進制數字序列,又稱字節。
37. 漢語拼音 (Pinyin)
給漢字注音和拼寫普通話的方案,採用聲母表和韻母表及拼寫規則。
38. 平面 (Plane)
是組(Group) 的其中一部分,共有256 x 256個編碼位。(見組)
39. 表示形式 (Presentation Form)
在一些文字中,用來表示一個圖形符號字符的形式,而該圖形符號的具體形式依賴於該字符相對於其他字符的位置。
40. 專用區 (Private Use Area)
基本多文種平面(BMP)中的一個指定區(從E000到F8FF),其內容未經ISO/IEC
10646定義,不可交換。
41. 專用平面 (Private Use Plane)
ISO/IEC 10646指定的用戶自行定義的平面,其內容未經ISO/IEC 10646定義,不可交換。
42. 部首 (Radicals)
漢字所選用的部件用于字典中的索引作為查找漢字之用。康熙字典中有214個傳統漢字部首。(參見
- 漢字字符、漢字)
43. 字匯 (Repertoire)
用編碼字符集表示的一個指定的字符集合。(參見 - 編碼字符集)
44. 行 (Row)
是平面(Plane) 的其中的一部分,共有256個編碼位。在二維數組中,單元表示豎向軸上的值。(參見
- 編碼位)
45. 源字集 (Source)
ISO/IEC 10646-1:1993中的中、日、韓統一漢字字符集包含20,902個漢字。它們是從超過54,000個來自於多個不同的國家和地區的編碼字符集標準中的漢字中甄選出來的。這些所使用的國家和地區的編碼字符集標準被稱為源源字集。
46. 筆畫 (Stroke)
構成漢字字形的最小連筆單位。如:“一”(橫)、“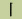 ”(豎)、“ ”(豎)、“ ”(撇)、“ ”(撇)、“ ”(點)、
“ ”(點)、
“ ”(捺)和“ ”(捺)和“ ”(折)。 ”(折)。
47. 筆數 (Stroke Count)
構成一個漢字或漢字部件的筆畫數目。
48. 筆形 (Stroke Feature)
筆畫的具體書寫形狀。漢字的筆形依據筆勢和走向可以分為數十種,其基本的類別為“一”(橫)、“”(豎)、“”(撇)、“”(點)﹝包括“”(捺)﹞和“”(折)。
49. 筆順 (Stroke Order)
書寫每個漢字時筆畫的次序和方向。
50. 輔助平面 (Supplementary Plane)
容納尚未編入基本多文種平面中的字符的平面。(參見 - BMP)
51. 代理對 (Surrogate Pair)
是UCS-2中一種用一對特定區域的編碼來表示一個字符的方法,其高字節在高半代理區,低字節在低半代理區。它提供了只用UCS-2的基本多文種平面雙字區位碼來表示基本多文種平面以外字符的機製並可表示16X64K
個字符。(參見 - 高半代理區,低半代理區, UCS-2)
52. 轉碼 (Transcoding)
不同字符集之間的字符數據轉換。
53. 轉換格式 (Transformation Format)
將一組編碼字串(按字節)轉換到另一編碼串的映射關系。(參見 - UTF,UTF-8,UTF-16)
54. UCS-2
ISO/IEC 10646 中用2字節編碼的方式,其編碼區為 U+0000 到 U+FFFF。
(參見 - BMP)
55. UCS-4
ISO/IEC 10646 中用4字節編碼的方式。其編碼區為 U+00000000 到 U+EFFFFFFF
(參見 - BMP)
56. 統一碼 (Unicode)
統一碼是是ISO/IEC 10646的實現碼。它不僅定義了ISO/IEC 10646中的所有字符,並且定義了一些字符的動
作方式。例如:將復合序列顯示成單個符號,將換行符變成光標的移動等。
57. UTF
是《統一碼轉換格式》的縮寫。
58. UTF-8
是八位統一碼轉換格式。將統一碼的數值(碼位)變成一串1到4字節的(變長)編碼。(參見
- 轉換格式,UTF)
59. UTF-16
是十六位統一碼轉換格式。將統一碼的數值(碼位)變成一串2字節的(定長)Big-endian
或Littie-endian編碼。(參見 - 轉換格式,UTF,Big-endian, Little-endian)
60. 區 (Zone)
編碼表中的編碼位序列,由一行或多行組成,可能全部或是其中一部分,包含特定類別的字符。(參見
- 單元、行)
|
