|
Glossary
1. Basic
Component
The smallest components that are considered one unit in a Hanzi
structure and are not further decomposed, such as "��"
and "�O"
in Hanzi character "�k".
(See Chinese Character Component�^
2. Big5
The industrial standard character set used in Taiwan and Hong Kong
for Traditional Chinese characters. It has about 13,000 characters.
(See also GB, Unicode)
3. Big-endian.
A computer architecture that stores multiple-byte numerical values
with the most significant byte (MSB) values first. (See Also UTF-16)
4. Block
A contiguous range of code positions to which a set of characters
that share some common characteristics, such as a particular script,
are allocated. A block does not overlap with another block. One
or more of the code positions within a block may have no character
allocated to it.
5. BMP
Abbreviation for "Basic Multilingual Plane". This is the first plane
in UCS-4 (Plane 00 of Group 00). It is also the main plane in the
2-Octet encoding.(See also UCS-4, UCS-2)
6. Canonical
form
The form with which characters of ISO/IEC 10646 are specified using
four octets/bytes to represent each character. UCS-4 is the canonical
form of ISO/IEC 10646. (See also UCS-4)
7. CC-Data-Element
Stands for Coded-Character-Data-Element. An element of interchanged
information that is specified to consist of a sequence of coded
representations of characters, in accordance with one or more identified
standards for coded character sets. For example, in some scripts,
they need to use accent characters, such as the diacritical character,
" "(U+ 0341)
in the Latin alphabet such as used on top of the letter " "(U+ 0341)
in the Latin alphabet such as used on top of the letter "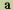 "
as appeared in " "
as appeared in "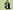 "(U+00E1).
In this example "" is not a character in the common sense, but it
is a data element which needs to be denoted in the standard. (See
also Coded Character Set) "(U+00E1).
In this example "" is not a character in the common sense, but it
is a data element which needs to be denoted in the standard. (See
also Coded Character Set)
8. Cell
Normally refers to a code point. In a 2-bytes encoding, a code point
is found first by locating its row number (first byte) and then
the cell, which corresponds to the column number (second byte).
In a 2-D matrix, cell usually represents the values along the horizontal
axis. (See also Row)
9. Character
An element used to represent, organize or control an independent
concept. A character usually refers to an independent writing element
in a language or an independent symbol. It can be (1) an element
of a computer character set; (2) an element of an alphabet; (3)
an element of the Hanzi, among other things. (See also Glyph, Hanzi)
10. Character
Boundary
Within a stream of octets/bytes the demarcation between the last
octet/byte of the coded representation of a character and the first
octet/byte of that of the next coded character.
11. Character
Decomposition
The process of separating or analysing a text element into component
units. These component units may not have any functional status,
but may be simply formal units or abstract shapes. Chinese characters
can be decomposed according to components or strokes.
12. Character
Encoding Scheme
A mapping from a character set to a set of octets/bytes. (See also
Character Set, Coded Character Set)
13. Character
Set
A collection of elements used to organize, control, or represent
information on a computer. (See Coded Character set)
14. Character
Unification
The process of replacing a number of potential elements of a character
set with one actual element. The criteria for unification may be
according to abstract form, abstract function, or both. Unification
is to avoid assigning multiple code points to some elements/characters
that are basically the same.
15. Chinese
Character Component
An ideograph unit with one or more strokes, which is often used
as a single unit to compose a Chinese character. For example, "��,
��, �f, �]".
All Chinese radicals are considered components. (See Radicals)
16. CJK
Ideographs
A set of Chinese (Simplified/Traditional), Japanese, Korean, and
Vietnamese universal coded Hanzi defined in the ISO/IEC 10646 standard.
(See also Hanzi)
17. CJK
Ideographs Unification
The ideographs in the ISO/IEC 10646 are derived from the source
standards by applying a set of unification procedures. The purpose
is to avoid giving multiple code points to CJK ideographs that are
basically the same with slight variation in shape. Ideographs that
are unrelated in historical derivation have not been unified. An
association between ideographs from different sources is made here
if their shapes are sufficiently similar, according to the two-level
classification to differentiate (a) between abstract shapes and
(b) between actual shapes determined by particular typefaces.(See
Source)
18. Coded
Character
A character together with its coded representation.
19. Coded
Character Set
A character set in which each character is assigned a numeric code
value. Frequently abbreviated as character set when the context
is sufficient to determine what is intended. (See Character Set)
20. Combining
Character
A member of an identified subset of the coded character set of ISO/IEC
10646 intended for combination with the preceding non-combining
graphic character, or with a sequence of combining characters preceded
by a non-combining character. For example, ""
in ISO/IEC 10646 is defined as a combining character, it can then
be used with a non-combining character ""
to form the character "".
21. Compatibility
Character
A graphic character included as a coded character of ISO/IEC 10646
without regards to unification primarily for compatibility with
existing coded character sets to guarantee round-trip conversion.
�]See Also Transcoding�^
22. Composite
Sequence
A sequence of graphic characters consisting of a non-combining character
followed by one or more combining characters. For example U+00E1
U+0341 U+0322 is a composite sequence (See also Combining Characters)
23. Glyph
Glyph refers to the actual shape of a character. A Chinese character
glyph gives the geometric structure, such as strokes, components
and relative positions of the strokes and components. (See also
Character)
24. Graphic
Character
A character, other than a control function, that has a visual representation
and can be handwritten, printed, or displayed.
25. Graphic
Symbol
The visual representation of a graphic character or of a composite
sequence. (See also Composite Sequence, Graphic Character)
26. Group
A subdivision of the coding space in ISO/IEC 10646. There are 128
groups in ISO/IEC 10646�A with each group has 256 planes of 256
rows by 256 columns, a total 256 x 256 x 256 cells in each group.
27. Guo
Biao (GB)
The National standard character set of P.R. China used in Mainland
China, Singapore, and other places that use Simplified Chinese characters.
(See also Big5, Unicode)
28. Han
Characters
Ideographic characters of Chinese origin.
29. Hanzi
The notation system of Chinese writing. Hanzi is also used by other
nations and nationalites for writing notation. The term is often
used with Han Characters interchangeably. (See Han Characters)
30. High-half
Zone (Range: U+D800-U+DBFF)
A set of cells reserved for use in UTF-16 as the high-byte in a
surrogate pair to represent characters beyond BMP range. (See also
Low-half Zone,Surrogate Pair, and UTF-16)
31. Ideograph
Ideograph refers to writing systems in which the scripts are not
primarily used to represent sound, but to represent meaning. Han
characters are often referred to as ideographs. (See also Han Characters)
32. Interchange
The process of transferring character coded data from one user to
another, using telecommunication means or interchangeable media,
with no loss of data. (See also Coded Character)
33. Internetworking
The process of permitting two or more systems, each employing different
coded character sets, meaningfully to interchange character coded
data; conversion between the two codes may be involved. (See also
Coded Character Set)
34. Little-endian
A computer architecture that stores multiple-byte numerical values
with the least significant byte (LSB) values first. (See Also UTF-16)
35. Low-half
Zone (Range: U+DC00-DFFF)
A set of cells reserved for use in UTF-16 as the lower-byte in a
surrogate pair to represent characters beyond the BMP. (See also
High-half Zone, Surrogate Pair, UTF-16)
36. Octet
An ordered sequence of eight bits considered as a single unit, also
known as a Byte.
37. Pinyin
The standard way of Romanising Mandarin Chinese in Mainland China
and in most other places around the world.
38. Plane
A subdivision of a group of 256 x 256 cells.
39. Presentation
Form
In the presentation of some scripts, a form of a graphic symbol
representing a character that depends on the position of the character
relative to other characters.
40. Private
Use Area
An area in BMP (from E000 to F8FF) whose content is not specified
in ISO/IEC 10646 and any data defined in this range is not meant
for exchange.
41. Private
Use Plane
A plane in ISO/IEC 10646 whose content is not specified and any
data defined in this plane is not meant for exchange.
42. Radicals
A component of a Han character (Hanzi) which is designated as the
indexing unit in the dictionaries. The number of such radicals in
the traditional Chinese dictionary, KangXi Dictionary, is 214. (See
also Han Character, Hanzi)
43. Repertoire
A specified set of characters that are represented in a coded character
set. (See also Coded Character Set)
44. Row
A subdivision of a plane of 256 cells. In a 2-D matrix, cell usually
represents the values along the vertical axis. (See also Cell)
45. Source
CJK Unified Ideographs in ISO/IEC 10646-1:1993 contains 20,902 ideographs.
They are derived from over 54,000 ideographs that are found in various
different nationals and regional coded character standards, which
are referred to as the "sources".
46. Stroke
The smallest writing unit without disconnection, such as
"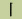     ". ".
47. Stroke
Count
Total number of strokes to construct a Hanzi glyph or a component.
48. Stroke
Feature
Absolute shape of a stroke. It can be classified by numbers of types.
The basic types include strokes of "".
49. Stroke
Order
The sequence and direction of strokes when writing a Hanzi.
50. Supplementary
Plane
A plane that accommodates characters which have not been allocated
to the Basic Multilingual Plane. (See also BMP)
51. Surrogate
pair
It is a coded character representation in UCS-2 for a single abstract
character that consists of a sequence of two code units, where the
first unit of the pair is in the high-half zone and the second is
in the low-half zone defined in BMP only. Surrogate pairs provide
a mechanism in UCS-2 to support another 16X64K number of characters
by using only the code range in BMP. (See Also High-half Zone, Low-half
Zone, UCS-2)
52. Transcoding
Conversion of character data between different character sets.
53. Transformation
Format.
A mapping from a coded character sequence to a unique sequence of
code units (typically bytes). (See Also UTF, UTF-8, UTF-16)
54. UCS-2
ISO/IEC 10646 encoding form which encoding a character in 2 octets.
It's code range is U+0000 to U+FFFF (See also BMP)
55. UCS-4
ISO/IEC 10646 encoding form which encoding a character in 4 octets.
It's code range is U+00000000 to U+EFFFFFFF(See also Canonical Form,
BMP)
56. Unicode
Unicode standard is the implementation of ISO/IEC 10646. That is,
it defines all characters in ISO/IEC 10646. In addition, it also
defines the behaviour of certain characters in ISO/IEC 10646 such
as displaying a composite sequence as a single symbol on the screen,
and trigger cursor movement when seeing a , etc.
57. UTF
Abbreviation for "Unicode (or UCS) Transformation Format".
58. UTF-8
Unicode (or UCS) Transformation Format, 8-bit encoding form. UTF-8
is the Unicode Transformation Format that serializes a Unicode scalar
value (code point) as a sequence of one to four bytes. (See Also
Transformation Format, UTF)
59. UTF-16
Unicode (or UCS) Transformation Format, 16-bit encoding form. The
UTF-16 is the Unicode Transformation Format that serializes a Unicode
scalar value (code point) as a sequence of two bytes, in either
big-endian or little-endian format. (See Also Big-endian, Little-endian,
Transformation Format, UTF)
60. Zone
A sequence of cells of a code table, comprising one or more rows,
either in whole or in part, containing characters of a particular
class. (See also Cell, Row)
|