|
在C/Linux程式語言上
與Microsoft Windows不同,Linux是使用UTF-8的。
當你在 Linux 平台上使用Unicode前,請檢查你的glibc版本是不是 2.2,和
XFree86 4.0 或更新的版本。舊的版本不支援 UTF-8,也沒有 ISO10646-1
X11的字體。
在Linux上有兩個方法加入UTF-8的支援。你可以將所有資料都儲存為 Unicode,這麼軟件的改動
並不會太大。另外亦可以使用 standard C library 把被讀取的UTF-8 資料轉換成
wide-character 數組輸出,再用程序 wcsrtombs() 把字串轉換回Unicode:

一般程式以計算字節長度的形式來計算文字,但在 UTF-8 應用程式上以計算
連續字節長度的方法是不可行的,所以要作出一些改動。如果應用程式是以UTF-8執行,C
library strlen(s) 程序便要以 mbstowcs() 來取代:

strlen 的其中一做普遍用法是計算畫面的輸出寬度。每個中文字符或其他象形文字會佔用2
個字節寬。wcwidth()這個函數是用來測試每個字所佔的畫面輸出寬度:

由 GNU glibc 2.2 開始,wchar_t 只會是用作 32-bit ISO 10646 的數值,和任何地區語言設定無關。當你在應用程式中設定
__STDC_ISO_10646__ (ISO C99 中要求),此功能將會被啟動。 __STDC_ISO_10646__
是用來分別此應用程式是否使用Unicode,正確的數值格式是 yyyymmL 。例如:
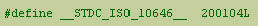
理想的啟動UTF-8 方法是使用 POSIX區域機制。區域是指一組設定包含一些需要套用在軟件和地區文化語言的有關資料;包括編碼、日期/時間格式、排列和度量衡制度。區域名稱一般包含
ISO 639-1 語言,ISO 3166-1 國家編碼及其他有關資料。你可以使你的系統指令
locale -a (一般在 /usr/lib/locale/ 中),用來列出系統中已安裝的區域。
如果你想從其他編碼標準 (例如 大五碼) 轉換至Unicode,可以寫一個 Perl
script 來建立一個數組,把原有的編碼作為索引,目標編碼作為值。(內碼轉換表可從本網站下載)
。再使用常規表達來作轉換的工程作。
|
