|
Unicode Programming
in C/Linux
Unlike Microsoft Windows, Linux uses UTF-8. Before you start using
UTF-8 under Linux make sure the distribution has glibc 2.2 and XFree86
4.0 or newer versions. Earlier versions lack UTF-8 locale support
and ISO10646-1 X11 fonts.
There are two approaches for adding UTF-8 support to a Linux application.
First, data is stored in UTF-8 form everywhere, which results in
only a very few software changes (passive). Alternatively, UTF-8
data that has been read is converted into wide-character arrays
using standard C library functions (converted). Strings are converted
back to UTF-8 when output as with the function wcsrtombs():

Small changes are needed for programs that count characters by counting
the bytes. In UTF-8 applications do not count any continuation bytes.
The C library strlen(s) function needs to be replaced with the mbstowcs()
function if a UTF-8 locale has been selected:

A common use of strlen is to estimate display-width. Chinese and
other ideographic characters will occupy two column positions. The
wcwidth() function is used to test the display-width of each character:

Officially, starting with GNU glibc 2.2, the type wchar_t is intended
to be used only for 32-bit ISO 10646 values, independent of the
currently used locale. This is signaled to applications by the definition
of the __STDC_ISO_10646__ macro as required by ISO C99. The __STDC_ISO_10646__
is defined to indicate that wchar_t is Unicode. The exact value
is a decimal constant of the form yyyymmL. For example, use:
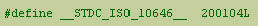
The proper way to activate UTF-8 is the POSIX locale mechanism.
A locale is a configuration setting that contains information about
culture-specific conventions of software behavior. This includes
character encoding, date/time notation, sorting rules and measurement
systems. The names of locales usually consist of ISO 639-1 language,
ISO 3166-1 country codes and optional encoding names and other qualifiers.
You can get a list of all locales installed on your system (usually
in /usr/lib/locale/) with the command locale -a.
If you want to convert from other encoding standard (e.g. Big5)
to Unicode, you can write a Perl script, generate an array that
contains the original code as the index, and the target code as
the value. The use regular expression to substitute the Big5 code
to Unicode.
|