|
在Microsoft Visual C++ 程式語言上
在Visual C++ 上使用Unicode非常容易,你只需要在include file中的首行加入define
_UNICODE。
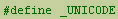
每一個Win32函數的原型在WINDOWS.H上都依照在編譯時間時是否包含UNICODE符號的巨集,來決定是否義了UNICODE
。 (一般在編譯器的參數上加入 -DUNICODE) 。如果定義了UNICODE標識,編譯器會在所有函數後加上W
(表示Wide character)。如果沒有定義UNICODE標識,編譯器會在所有函數後加上A
(表示ANSI)。WINDOWS.H也定義了generic data types (TCHAR, LPTSTR)
和數據結構。如果使用這些generic declarations,便能使用同一個原始碼檔案
來編譯成支援Unicode或ANSI的程式。
每一個wide character是一個2 字節的多國語言字符編碼。在現今電腦應用上,只要Unicode有收錄的字符(包括所有符號和一些出版上的特別字符),都能以一個Unicode
wide character的形式輸出。因為每一個wide character都是16-bits 定長的,所以使用上能簡化多國語言程式設計上的困難。
每一個wide character的字串能以一個wchar_t[] 數組的形式表示,並以一個
wchar_t* 的指針指著。任何ASCII字符都能以wide character的形式表示,但必須在ASCII字符前加上L字符。例如,L'\0'代表一個16-bits寬的終止字符。同樣,一般ASCII字串都能以wide
character字串的形式表示,但必須在ASCII字串前加上L字符。例如,L"Hello"。
要使用wide character作為支援,在字串前加上L字符或使用wchar_t[]都不是好的方法。最合適的方法是在字串前加上
_T字符或使用 _TCHAR[],這是一個generic data type。如果定義了UNICODE標識,數據類型便會定義為wide
character。如果沒有定義UNICODE標識,數據類型便會定義為ANSI char。
一般來說,wide character雖然比多字節字符佔用較多的記憶體空間,但處理速度較快。相對於以多字節的形式編碼只能每次代表一種語言,Unicode編碼卻能同一時間代表全世界已收錄的字符組合。
除了資料庫類別 (ODBC並不支援Unicode) ,在MFC的架構中是支援Unicode的。MFC是依靠"可攜式"巨集來支援Unicode的,如下圖所列:

CString類別以 _TCHAR作為基本,它提供了constructors 和operators以方便處理轉換。其基本的運算以16-bits取代8-bits來處理,所以大部分的Unicode字串運算
都可利用此邏輯來處理Windows ANSI字集。與其他多字節字集不同,你不需要
(也不應該)將兩個獨立的bytes當作一個Unicode字。
|
