|
Unicode Programming
in Microsoft Visual C++
Using Unicode in Visual C++ is an easy task. All you have to do
is define _UNICODE at the top of the include file, like this:
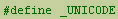
Each Win32 function prototype in WINDOWS.H is a macro that expands
based on whether the compile-time symbol UNICODE is defined (usually
by adding -DUNICODE to the compiler's command line). If the UNICODE
flag is defined, the compiler appends a W (for Wide character) to
the function names. If the Unicode flag is not defined, the compiler
appends an A (for ANSI). WINDOWS.H also defines generic data types
(TCHAR, LPTSTR) and data structures. With generic declarations,
it is possible to maintain a single set of source files and compile
them for either Unicode or ANSI support.
A "wide character" is a two-byte multilingual character code. Any
character used in modern computing worldwide, including technical
symbols and special publishing characters, can be represented according
to the Unicode specification as a wide character. Because each wide
character is always represented in a fixed size of 16 bits, using
wide characters simplifies programming with international character
sets.
A wide-character string is represented as a wchar_t[] array and
is pointed to by a wchar_t* pointer. Any ASCII character can be
represented as a wide character by prefixing the letter L to the
character. For example, L'\0' is the terminating wide (16-bit) NULL
character. Similarly, any ASCII string literal can be represented
as a wide-character string literal by prefixing the letter L to
the ASCII literal (L"Hello").
If you want wide char support, it is no good to use either a prefix
L or wchar_t[] to represent a wide character. The best way is to
use prefix _T or _TCHAR[], because it is a generic data type, the
data type will be declare as a wide character if the UNICODE flag
is defined, and a primitive char if the UNICODE flag is not defined.
Generally, wide characters take more space in memory than multi-byte
characters but are faster to process. In addition, only one locale
can be represented at a time in multi-byte encoding, whereas all
character sets in the world are represented simultaneously by the
Unicode representation.
The MFC framework is Unicode-enabled throughout, except for the
database classes. (ODBC is not Unicode-enabled.) MFC accomplishes
Unicode enabling by using "portable" macros throughout, as shown
in the following table:

Class CString uses _TCHAR as its base and provides constructors
and operators for easy conversions. Most string operations for Unicode
can be written by using the same logic used for handling the Windows
ANSI character set, except that the basic unit of operation is a
16-bit character instead of an 8-bit byte. Unlike working with multibyte
character sets (MBCS), you do not have to (and should not) treat
a Unicode character as if it were two distinct bytes.
|